
Welcome to the official website for Exodus, a unique and powerful emulation platform. Please use the main menu above to learn more about Exodus, and to gain access to support and downloads.
I'm going to start using this news feed as a development blog, to keep people updated with what's happening with upcoming changes, and how development is going in general.
Right now I'm trying to break through a barrier to cycle accurate emulation that no software emulator has done to date. The 68000 processor in the Mega Drive is clocked at around 7.61Mhz, meaning 7,610,000 cycles per second. A single opcode usually takes between 4 and 40 of those cycles to execute, but it can be a lot more than that for MOVEM opcodes, and potentially hundreds for multiply and divide operations. Here's the kicker - the 68000 processor can release the bus to share with other devices, such as for DMA operations from the VDP, or banked memory access from the Z80. The real 68000 processor will respond to bus requests within 2 cycles, or if it's currently actively performing a bus operation itself, at the end of the current bus cycle (4 cycles typically, but can be longer). This means there are around 3,805,000 timing points each second where external requests to obtain the bus need to be checked and responded to in order to get perfect timing accuracy. Right now, Exodus only checks between opcodes, meaning most bus ownership requests are delayed. Most other emulators only synchronise between cores and check for access requests at fixed points, usually thousands of cycles in length. Both are incorrect, and can easily impact timing sensitive code.
There are several challenges in overcoming this barrier. The first is performance. If you want to respond to bus requests accurately within 2 cycles, you need to be checking at 3,805,000 points during execution of your 68000 core for bus access requests each second, and more than that, you need to keep your cores "in sync" so that you don't find out about an access attempt after you've already passed the time when it should have been processed. There is an unavoidable performance hit in doing this. Exodus has a design that aims to minimize that cost, but it will be there. Most of it is already being taken by the platform, hence why Exodus requires more processing power than most (all?) other Mega Drive emulators out there. It was designed to solve these problems, but that means an execution model which has a lot more overhead for synchronisation, because synchronisation is happening a lot more frequently. That's the cost of cycle accurate emulation.
The second barrier is the more annoying one IMO. Your "traditional" emulation core would step through one instruction at a time. If the next instruction is an ADD opcode, you execute it in one go. That's simple, logical. Let's simplify and say it looks something like this:
void AddOpcode(source, target)
{
sourceData = source.read();
targetData = target.read();
result = sourceData + targetData;
target.write(result);
}If you now can grant the bus at between 1 to 13 discrete points within the execution of that single opcode though (for ADD this is correct), what does that look like in code? You can't just call a single linear function for that opcode with one entry and return point anymore. You could try and have blocking calls within the function, so that the execution of the AddOpcode function is suspended until the bus is returned... but then you can't do savestates, because how can you save the current execution state and resume it later when you leave a blocked thread like that? You could try and wait for the processor to be between opcodes for a savestate request to be actioned, but what if you have two processors constantly swapping the bus between each other? They might never reach a point where both are between opcodes and all threads are unblocked.
The best way forward is to turn your opcode execution steps into a kind of state machine, where you can step through the opcode one internal step at a time. That makes the code unfortunately more verbose, and much less branch predictor friendly, so slower, but it looks something like this:
bool AddOpcode(source, target, currentStep)
{
bool done = false;
switch (currentStep)
{
case 0:
sourceData = source.read();
break;
case 1:
targetData = target.read();
break;
case 2:
result = sourceData + targetData;
break;
case 3:
target.write(result);
done = true;
break;
}
++currentStep;
return done;
}This is what I'm currently working on doing for Exodus. This will give truly 100% perfect timing accuracy for the CPU cores, which will be essential when expansions like the MegaCD and 32x come along, which makes the number of bus interactions very complex.
There's actually more to it than this. Part of the work I'm currently doing involves adding perfect handling of DTACK to handle wait cycles during bus access, and group 0 exceptions like bus and address errors, but I'll write more about that at another time.
I'm happy to announce I have now started work on Exodus again. You can expect a fairly steady set of updates over the next few months as I get the repo into shape. No hard plans on what will be in the next release or when that will be, but it'll be coming during the year. I've also made the decision to simplify the licensing model, and as of today Exodus will be governed by the MIT license, a much more permissive licensing model. Feel free to use and adapt the code however you see fit. Any contributions or attribution you want to make back to this project would be greatly appreciated, but not required.
With the accelerating decline of Mercurial support in the industry in general, and the decision by Atlassian to drop Mercurial support from BitBucket in particular, it's past time for me to migrate the Exodus source repository to a new home. Although Exodus hasn't seen much love from me in recent years due to real life keeping me busy, I'm still here in the background biding my time until I can invest in this project again. To give the Exodus code a home until that happens, I've just migrated the repository over to GitHub. Although I have a fondness and personal preference for GitLab, GitHub has become the de-facto standard home for open-source projects over the last decade, and I see no reason to fight that trend. You can now find the Exodus source repository hosted under GitHub at https://github.com/exodusemulator/Exodus. Future development will be based from this location, and the website has been updated to reference this new home.
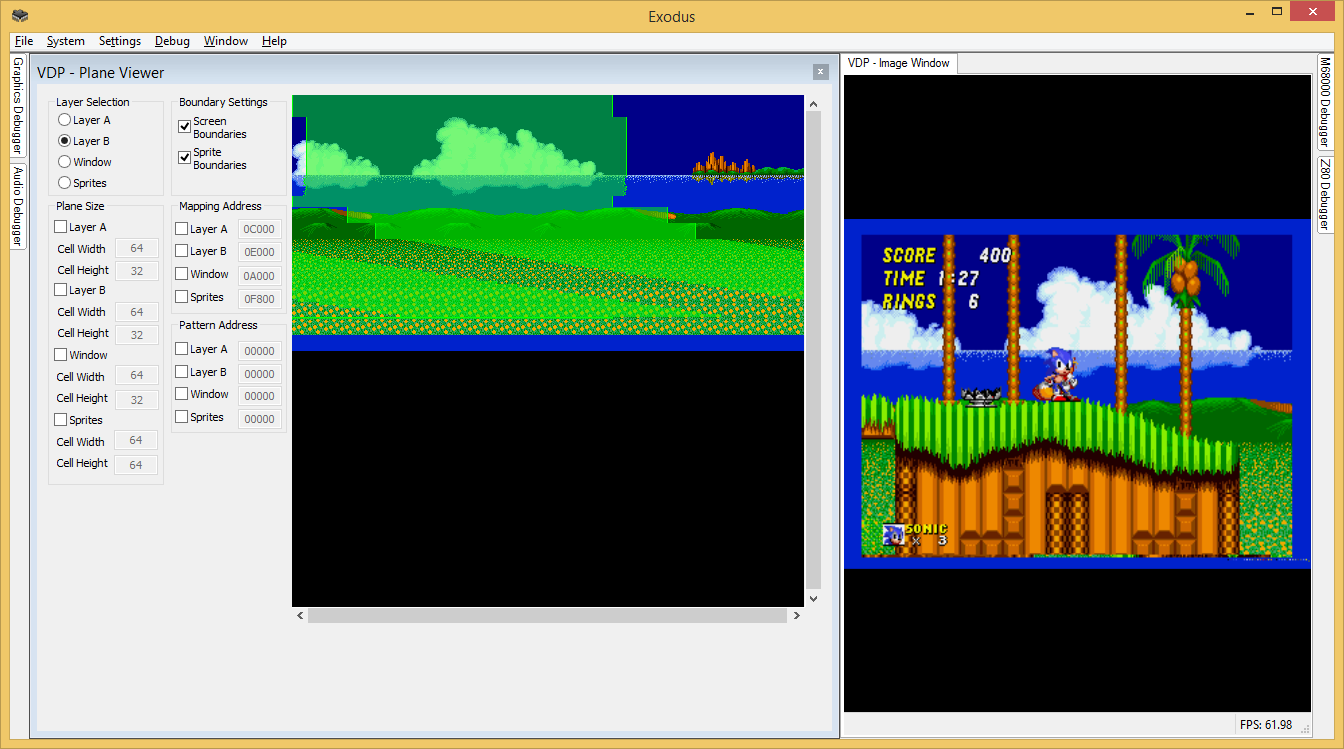
Exodus 2.1 is now available in the downloads area. Note that you'll need to install the Visual C++ 2017 x64 runtime too if you don't have it, which is available there too. There's quite an impressive list of bugfixes in this release. Job EX-303 in particular fixes a crash that could occur if you had a joystick or gamepad connected, which affected a fair number of people in the previous release. There's also pretty good performance improvements. I measure around a 30% speed improvement overall from Exodus 2.0.1, which is pretty substantial. I've made the VDP plane viewer a but nicer by making the window resizable and making the plane region zoomable, which is nice, but I'm particularly proud of this little nugget:
![]()
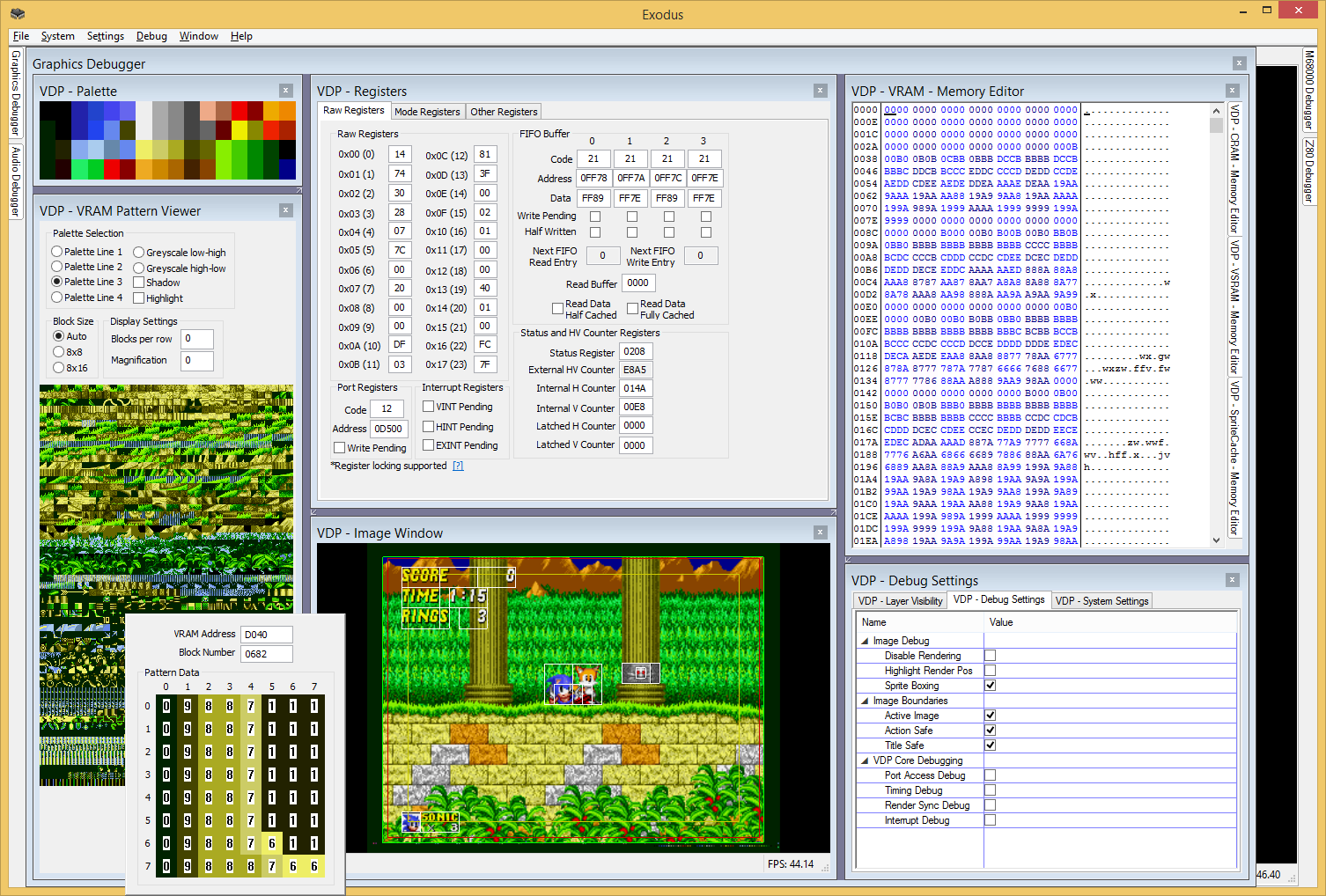
It's a pixel info dialog you can turn on via "Debug->Mega Drive->VDP->Debug Settings". Just float your cursor over any pixel, and it'll tell you exactly what caused it to appear there. This plays nice with layer removal, so you can peel off a layer at a time and see what's behind it if you want to, and where that pixel came from. It even works for CRAM writes during active scan. Being able to reverse the VDP render pipeline like this was relatively easy in Exodus because of how much info the VDP core holds on to, but it still took a bit of work to pull this off. Give it a spin and let me know what you think. It's great for diagnosing those mystery single line or pixel errors you can get while making something.
Here's the full list of user-facing changes in this release:
Enhancements:
Bug fixes:








If you wish to make a donation to show your appreciation for this project, you can do so here. Your donation may go towards the hosting costs of the website, or equipment or reference hardware to assist in the development of Exodus. It may also go towards a bunch of flowers for my beautiful wife, to say thanks for your support and patience all those nights I stayed up late working on this project.